The importance of data selection and uncertainty estimation
Data is key to the development of automated driving functions. In this article, Dr. Nico Schmidt, Machine Learning Architect at CARIAD, explains how we use data sets to train machine learning models, determine uncertainty and, ultimately, develop enhanced customer features.
At CARIAD, we use data sets for training and testing machine learning models, and ensure that they’re as diverse as possible with respect to traffic scenarios, regions and environmental conditions, for example. In this way, we can cover a larger application space and test that our ADAS/AD functions work in the places and situations where we want to deploy them.
We’re particularly interested in discovering and iteratively training data that improves model performance the most. We can then gradually select new data and add it to the training set to refine our model over time. This is accompanied by corner case detection, which even ensure that we have appropriate measures once we get out of our operational domain. Ultimately, we can develop new perception functions or expand existing functions by creating new data sets with scenario-based triggers and retrieval methods.
But first of all, let’s start with the basics.
Where do we find data?
In order to build data sets, we need data. We have three main data selection sources available to us, each with their own advantages and disadvantages.
The data lake gives us access to data from limited scenarios because it’s information that we’ve previously recorded. It contains data from the past, so it isn’t very up to date in our ever-changing world. On the other hand, it does offer us the advantage of heavy compute capabilities and therefore also the ability to analyze the whole data distribution at once.
The testing fleet consists of vehicles that are taken out to a specific region at a specific time in order to collect a specific kind of data. The information is very up to date but still limited in diversity of the scenarios because of the limited number of vehicles. However, we can integrate moderate compute resources to analyze the incoming data stream to select individual samples or snippets.
The customer fleet is the Holy Grail of the three data selection sources. Not only is it a huge fleet, with millions of Volkswagen Group vehicles, but it also gives us access to the open world. We can access virtually every possible scenario on the road, with instant snapshots of current situations. However, the ECUs in customer vehicles have limited compute capabilities. Like the testing fleet, they only offer us stream-based selection.
To accelerate the data-driven development process for our software platform, we recently launched our first development fleet. This fleet will consist of several hundred Volkswagen Group vehicles fitted with cameras, sensors and high-performance computers and allows us to prepare for series production years in advance.

What data is useful to us?
Most of the time, we drive around in relatively similar situations on the road. We already have a lot of data from these kinds of situations and our machine learning models perform well here. What we see as more informative are rare scenarios and corner cases. These are often safety-critical scenarios where our model and vehicles have the greatest opportunity to learn.
Corner cases may involve a weak or noisy sensor signal as a result of difficult weather conditions. Alternatively, there may be a context mismatch, where our model understands the individual objects but, when it sees them together in a strange combination, gets confused. Or it may be a situation where the car encounters an object that’s very rare and underrepresented in our data set.
How do we collect these rare cases and determine uncertainty?
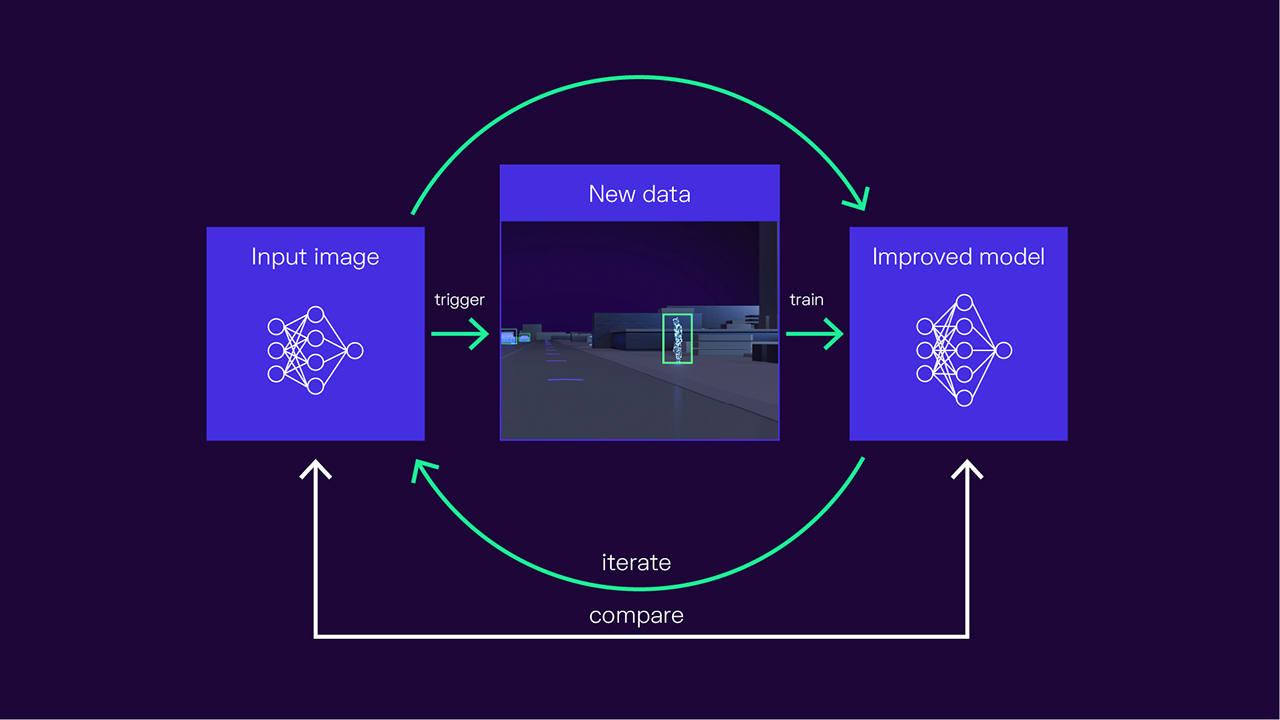
We can estimate the uncertainty of our machine learning models based on their own predictions and by using our INSTINCT software component, which Stefan Sicklinger introduced in his article on the Big Loop. Uncertainty estimation is just one of the many data collection methods integrated into INSTINCT.
To explain this, let’s take the example of traffic light detection. In this scenario, INSTINCT is watching out for traffic lights and computing uncertainty scores. The detection model receives images from the car’s cameras as input and detects traffic lights in them. We then apply our intelligent trigger to calculate an uncertainty score for each individual traffic light. The car might be certain that some objects are traffic lights, but unsure about others.
We then combine these individual scores to generate a collective uncertainty score for the entire image and define a particular uncertainty threshold. If this threshold is exceeded, it indicates that this image is of interest to us. The image is therefore recorded and sent to the cloud. If, on the other hand, the uncertainty score doesn’t cross that threshold, the image is disregarded. We don’t need to record the data, as it doesn’t add any value to our training. In this way, INSTINCT helps us to filter data and only show us useful data.

What do we do with this data?
Once INSTINCT has collected enough data, it can be used for multiple purposes. We can train a perception module, for example, which is one of the key building blocks of the traffic light detection feature.
After aggregating the data, we need to enhance it so that we can deploy supervised learning techniques to our perception module. We can use pseudo-labelling pipelines. After that, we then have data that can be used for training or testing. In our example, we’d train the perception module with the new data to improve its detection quality.
Once the sole rendered artefact has been verified through virtual testing and it’s been verified that the data gathered via INSTINCT and the Big Loop meets the design targets, we can then create a first release candidate of the traffic light detection feature. It can then be released to the protected area blade in the vehicle, and tested and scaled on the road under real-world conditions. After engineering and data testing has been completed, the new enhanced customer feature can be downloaded to the vehicle.

Join us in developing machine learning models for automated driving
At CARIAD, we’re always on the lookout for the brightest digital minds and tech experts to join our team and shape the future of automotive mobility with us. If you’re experienced in the fields of AI and data and fancy a new challenge, check out the relevant open positions below.

-
Before the final whistle: The software that drives us on matchday
 As the World Cup heads into its final week, connected vehicle software can help fans plan routes, charging, updates and the ride to kick-off.13/07/2026
As the World Cup heads into its final week, connected vehicle software can help fans plan routes, charging, updates and the ride to kick-off.13/07/2026 -
This pulse inverter makes small EVs feel big
 The Electric Urban Car Family launches with the Volkswagen Group’s first in-house pulse inverter, powered by CARIAD software. It brings high-end technology to entry-level mobility.05/06/2026
The Electric Urban Car Family launches with the Volkswagen Group’s first in-house pulse inverter, powered by CARIAD software. It brings high-end technology to entry-level mobility.05/06/2026 -
Inside the ID.S 6 Entertainment Hub
 ID.Software 6 features the new in-car Application Store. Developed by CARIAD, with direct access to 50+ applications it is available in the new Electric Urban Car Family.29/05/2026
ID.Software 6 features the new in-car Application Store. Developed by CARIAD, with direct access to 50+ applications it is available in the new Electric Urban Car Family.29/05/2026